ASCII Tabs Release
ASCII Tabs is a website to learn guitar and basic music theory; enough to jam with anyway. Today it is considered fully released, and should have no bugs. 🤞
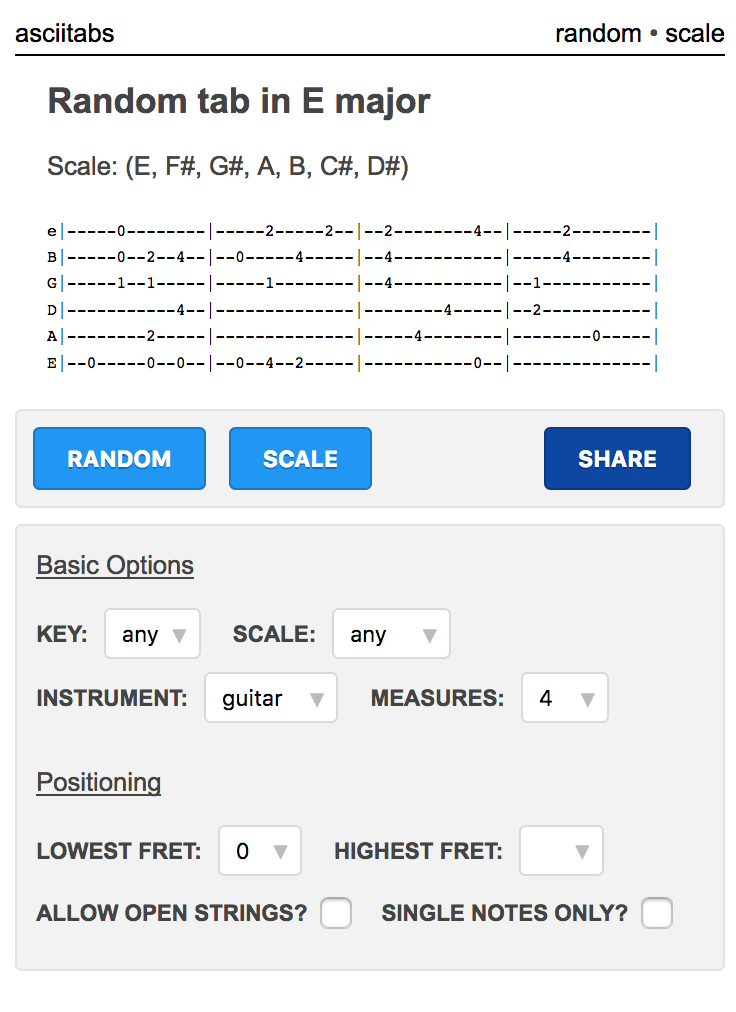
Features added since the beta release:
- Polished mobile device interface
- HTTPS / SSL support
- Allow for random tabs that only use single notes
- Allow for open notes in random tabs with fret limits
Unless better ideas are surfaced through feedback, the next feature I plan to add is optional highlighting of roots / thirds / fifths.
Enjoy!
Quake Timer
Download on Github
In the game Quake Champions, powerful items spawn around the map at fixed intervals. Collecting these items is the key to victory in higher-level games.
Unfortunately, the game only provides a thirty-second callout for the most powerful items (Quad Damage and its inverse – Protection), and does not provide any callout for the lesser items (Mega Health and Heavy Armor).
The Quake Timer App allows players to set their own timers to work around this. While playing, you can hit a key combination like ALT + 1 whenever a valuable item is picked up. The timer will then provide voiced callouts (e.g. “Mega Health in ten seconds”) before the items respawn.
Asciitabs Alpha
A month ago I released the alpha version of asciitabs.com. This post covers how the site started, how it was launched, what I learned from that launch, and where it will go from here.
I don’t really consider the launch to be successful, but it was a good learning experience. I believe with a few more features and market research it has potential to be a useful website.
How Asciitabs started
I have always found tablature to be the most approachable way to learn guitar and share amateur compositions online. There is a lot lost in translation between tabs and standard notation, but it seems like the difference between Markdown and LaTeX: both have a place and purpose.
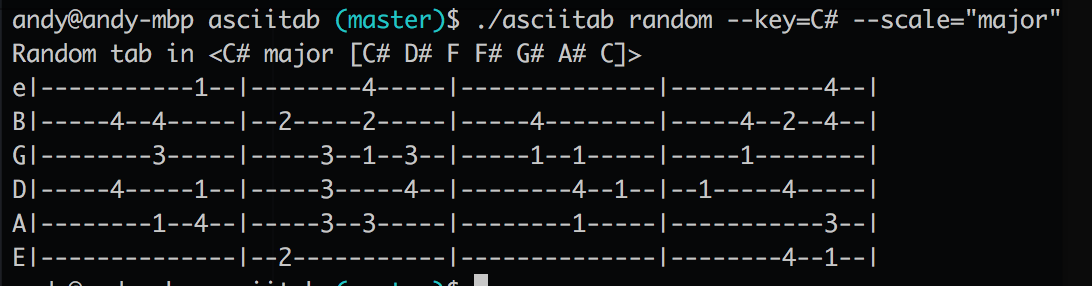
I wanted to practice my basic music theory, and my Go programming, so I created a command-line tool to generate random tabs given a key and a scale. I got this to a point where it could make random tabs and basic ascending scales before deciding to see if I could turn it into a more accessible website.
Creating the website
I marked my prototype as complete and left it up on Github for the curious. The repo was copied to a private Bitbucket repo for future work, which I hope maintains some semblance of a competitive advantage if the website ever gains traction. I hope to open source the core music-definition and tab-generation libraries once they have matured.
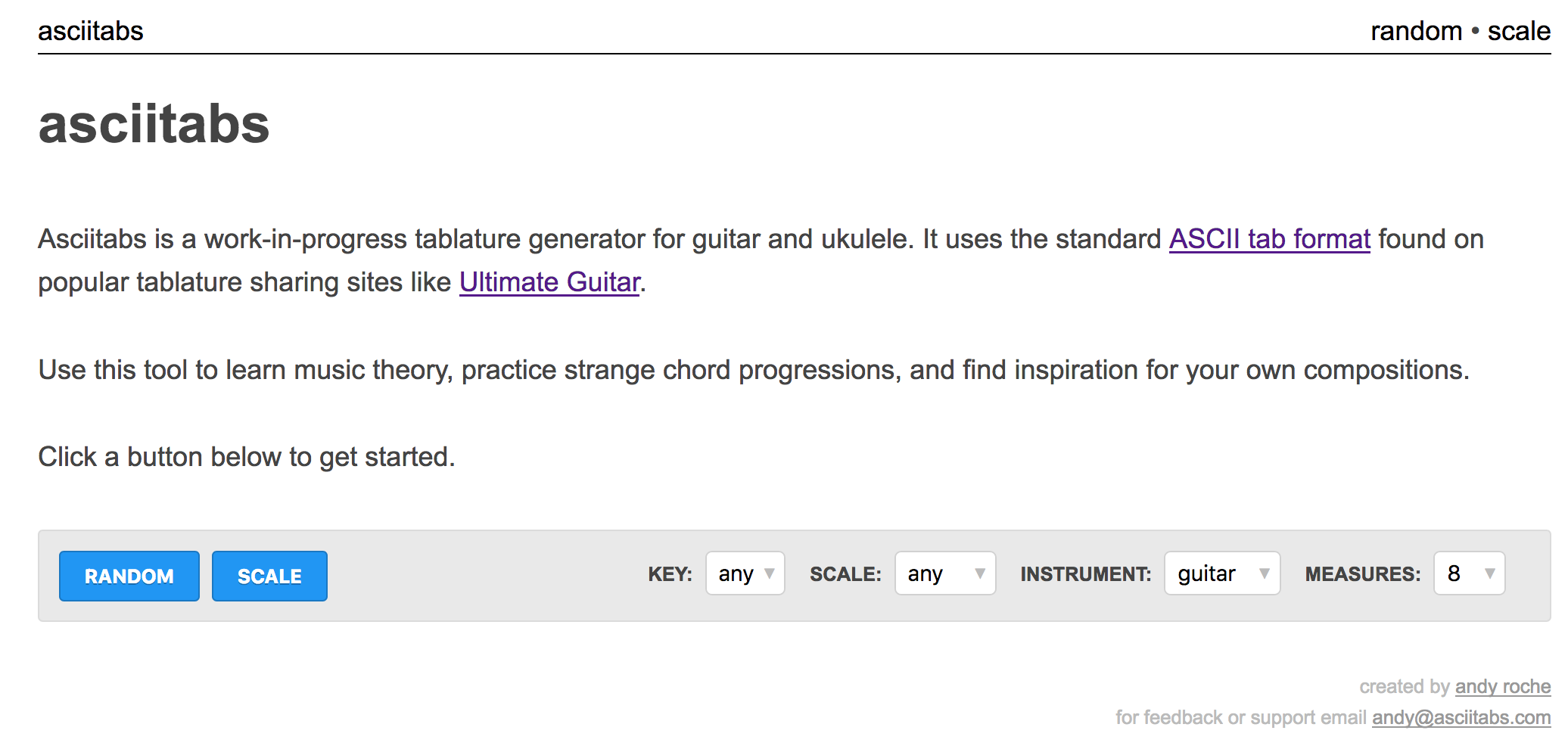
I built out a very basic web interface using the Go html/template and net/http standard libraries. The website is hosted on a single EC2 t2.micro instance and is deployed using Docker and ECR. I managed to get 50% test coverage on the core tab-generation library but had no testing on the CLI or website code at this point.
I released a pre-alpha to some of my friends and got an initial round of feedback, bug reports, and feature requests. By the end of that round, the website was in a minimally styled but fairly robust state, supporting: random tabs, scales, flats / sharps, majors / minors, guitar, and ukulele.

There were dozens of tweaks and features that I still wanted to add, but I decided to test the waters as early as possible, hoping that would help me decide what to focus on next.
Alpha launch and early feedback
I put the finishing touches on the site, made sure people knew how to contact me for feedback / bug reports, and posted it to Hacker News.
The early feedback was minimal, but was thankfully helpful, positive, and diverse. I got website feedback of the following nature:
- Mobile support was broken (easy fix - remove the
viewportsettings) - Request for plectrum / pick-centric tabs (easy feature)
- Request for in-browser audio output of the generated tabs (medium-hard feature)
My favorite comment was one not about my website, but about my future progression as a musician. The user recommended that I learn standard notation and not rely so much on tablature because of how limiting it is. I took this to heart in my practicing by trying to play songs from standard notation that I have already mostly memorized. It’s slow going, but sure to pay off in the long run.
The next day, I also submitted the site to Reddit at /r/UsefulWebsites. This got some more visitors and analytics data, but sadly no more direct user feedback.
Analytics data from launch
I wish I had more time to figure out a locally-hosted or privacy-centric analytics tool, but Google Analytics is just so good and free and easy. I’m sorry everyone. I assume most people that are offended by tracking have blocked those requests anyway, which also means that the data below is not 100% complete and accurate. Take this section as you will.
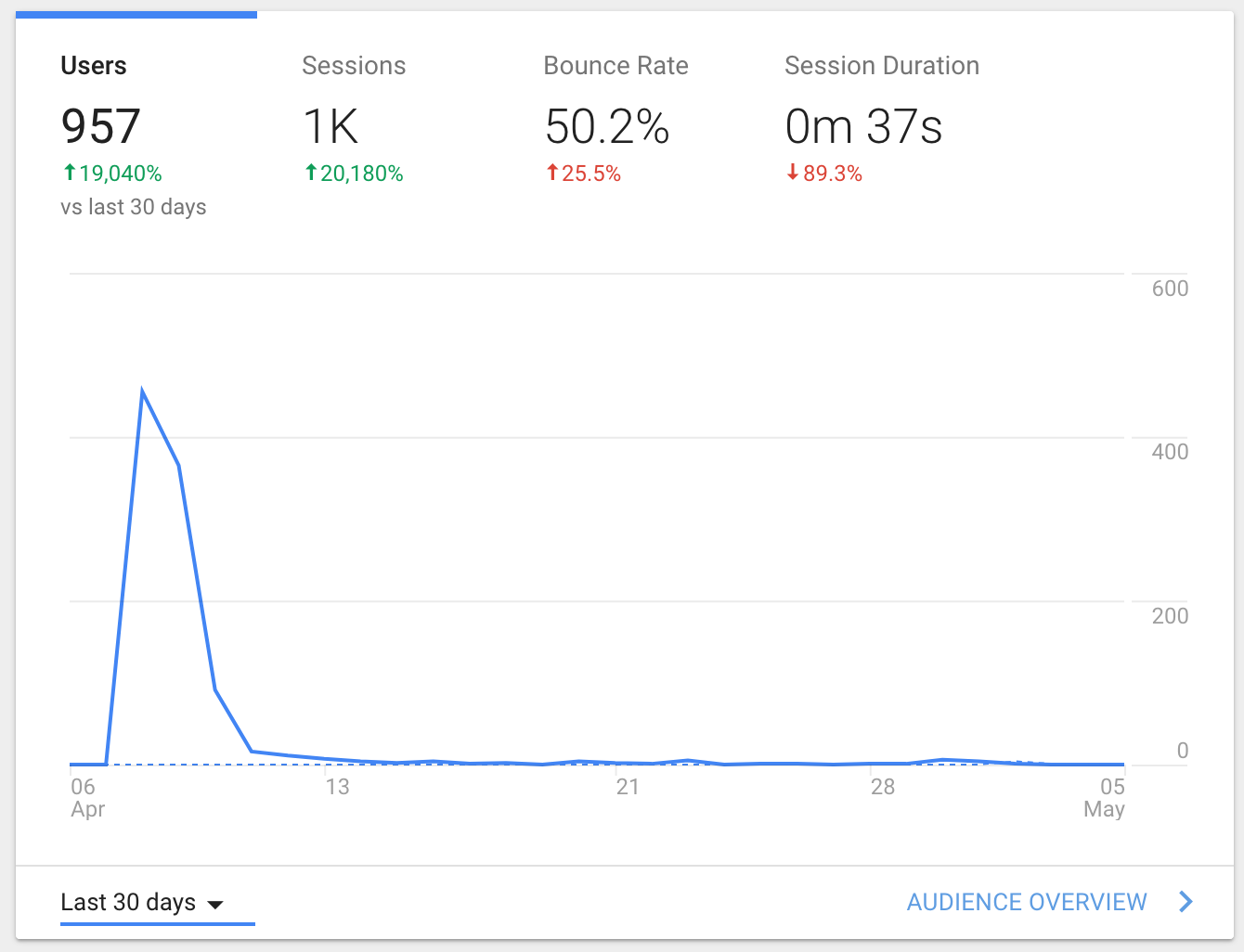
I got just under 1,000 visitors in 3 days, and have only seen at most 5 a day since then. I have not done any continued marketing since the two initial posts, and was curious to see if there was any latent virality in this idea. The answer was clear. I need to make the site more useful and catchy, and probably also need to consider some direct marketing if I ever monetize the site.
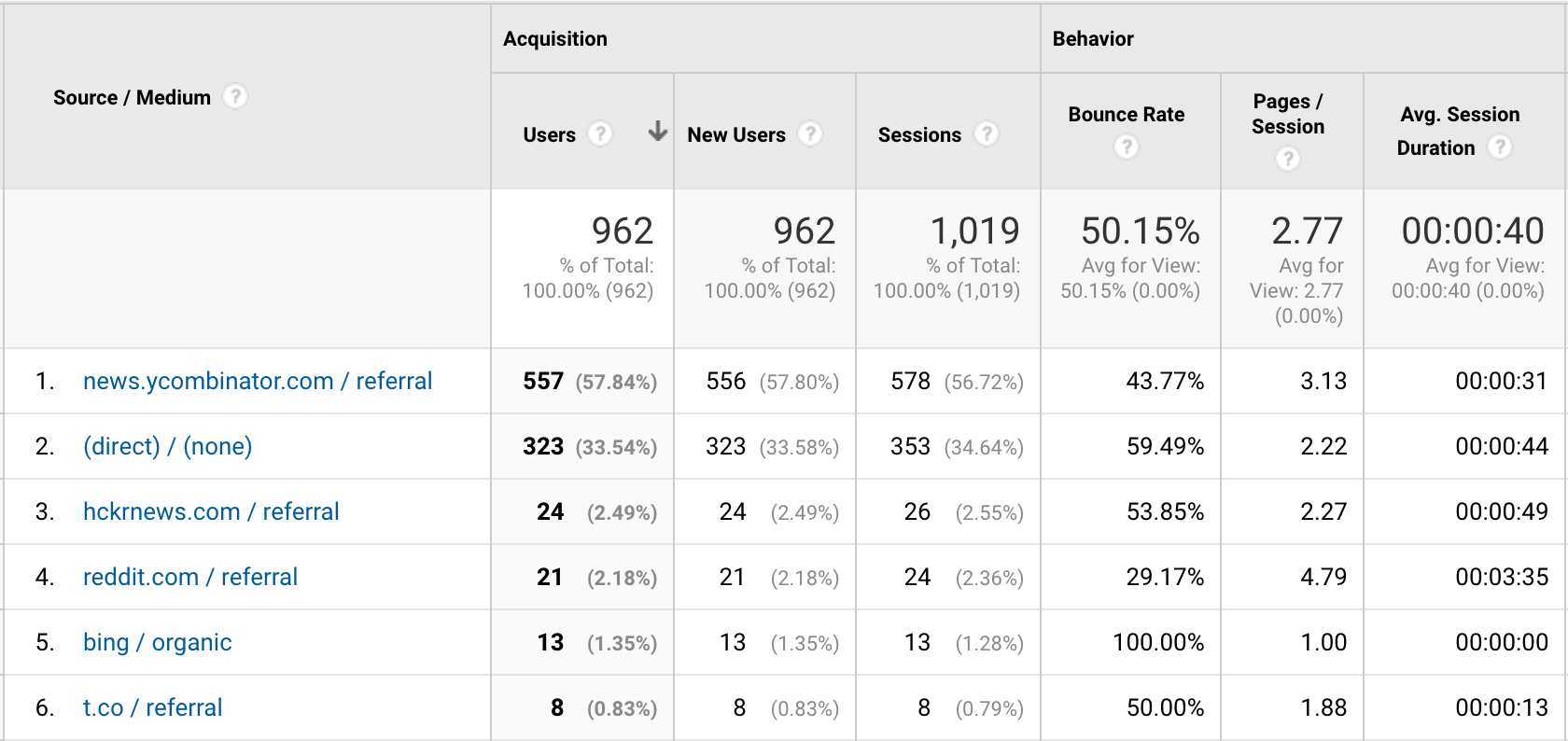
The source metrics show that most of my traffic came from the Hacker News post, but most of those users just toyed with a couple pages then left. The Reddit group stayed around a bit longer and seemed to show more interest in it, but there were a lot fewer of them.
All in all, not much useful data here other than that I clearly need to do more work if I want the website to be found by and useful to a wider audience.
Lessons learned
- The site needs more features
- More tab customization options
- Rhythm in tabs (spacing of chords)
- Custom instruments
- The site needs a way for people to share tabs easily
- The site needs monetization and direct marketing
- Only after further validation of base idea
- The site needs a better landing page
- Way to experience the app for non-musicians
Updates since launch
Since the original launch, I have begun to make progress on the lessons learned from above.
Index Page
The index page still retains above-the-fold simplicity and big call-to-action buttons, but also has a small description and GIF of the major “Random” and “Scale” features.
Sharing Modal
I added a sharing modal on the tab page that includes a link to the exact tab the user is viewing.
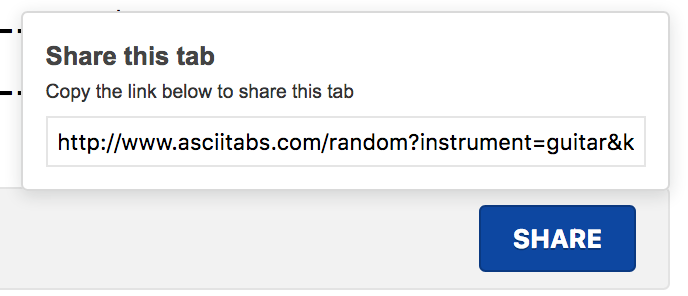
This was pretty easy to implement in Go by using rand.Seed for each tab generated, and passing that seed through to the page in case the user wants to share it. The final URL looks something like this:
http://www.asciitabs.com/random?instrument=guitar&key=Bb&measures=8&scale=minor&seed=53gw5f
I might make a small internal shortening service for that if it becomes too unwieldy.
More Options
I split the tab button bar from the options box, and now have a lot of room to grow out the options section without overwhelming a first-time user.
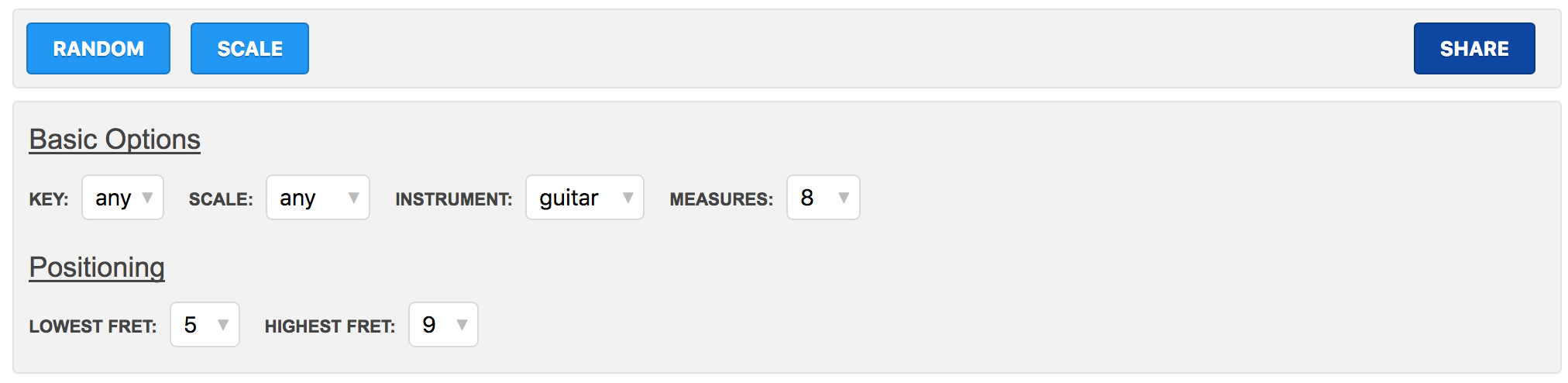
I knocked out a new feature here too for supplying a minimum and maximum fret for tabs - previously it would always just use frets 0 to 4 for random tabs and root to root + 4 for scales.
Programming Stuff
I added an official CHANGELOG and started doing git tags on releases. I also started unit testing my cli and web libraries and raised overall coverage to 60%. It’s not much, but sometimes it’s the little things that help you sleep at night.
Closing thoughts
The alpha launch of Asciitabs didn’t have the virality or continued usage that I was hoping for, but it has been one of my most successful sites so far. I’m going to keep building features and fixing bugs as I have time, but my mind is starting to wander off to other, possibly better, ideas.
Check out the site at asciitabs.com. If you have any feedback, feature requests, or bug reports, please send me an email at andy@asciitabs.com.
Haiku News Bot
This week I released my first bot on Twitter – HaikuNewsBot
It’s built in Python, and gets news from over 50 English sources using the free News API
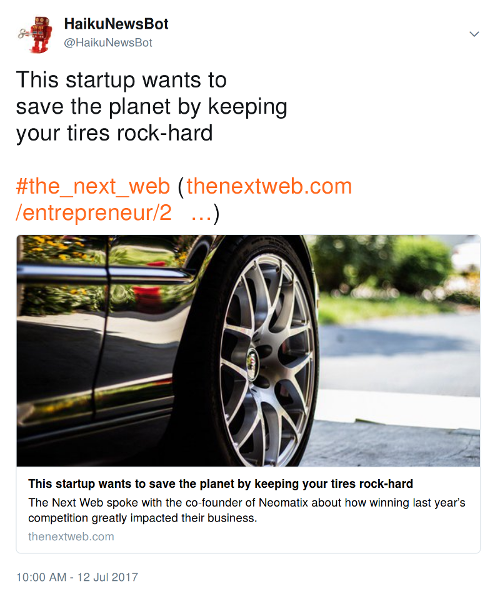
It’s not 100% accurate or super useful but it’s a cute proof of concept for future bots and parsing programs. I’ll add small updates over time as I receive feedback and notice bugs.
Parsing a Haiku
I settled on making this an English-only news bot, so I could use consistent (and familiar) language parsing techniques for every article title.
Most of the syllable counting logic is a combination of the CMU Pronouncing Dictionary from the nltk package, and the textstat package.
I wrote a custom syllable parser for numbers, so that ‘16,000’ is properly counted as four syllables (six-teen-thous-and). I also wrote a parser for acronyms, discovering that the translation of letters to syllables is wonderfully simple: 3 if letter == 'w' else 1.
I’ll wait while you go through the alphabet in your head now.
Before running words through the parsers, I .split() the headline on all whitespace, stripped it of non-alphanumeric characters, and analyzed each text element by itself.
If an element was 3 characters or less and uppercase (e.g. FBI), then assume its an acronym, and use the character parsing logic above.
If an element is composed of letters and numbers (e.g. G20 or patio11), then split the alpha part(s) from the numeric part(s), and parse each of those elements separately.
Collecting and Posting Tweets
Each time the bot runs, it gets about 15 new haikus from the API. It stores these in a local SQLite database, ranking them by haiku likelihood (it has about a 70% accuracy rate).
Whenever the bot is told to post a haiku, it chooses the highest-rated one from within the last day from the database. It tries to post it to Twitter, and does nothing if it fails (at the moment). Eventually I’d like to set it to email me if it fails with the error message.
Hosting the Service
The bot is hosted on a $5 Linode VPS with some other toy programs, and runs once an hour as a cron job (0 * * * *).
Where to Store API Keys
A common security issue that comes up when developing networked applications is where to store security credentials like API keys.
Basics
One of the first steps to securing API keys is to remember to never check them into source code repositories. If you ever commit and push code that includes a hard-coded API key, it is compromised, and you’ll need to revoke it and create a new one.
One option to store these keys is to read them from files not synced to the source code repo. The problem with this is when changing machines or working with multiple developers - its hard to pin down a consistent location to store these keys.
The next logical step is to store them in Environment Variables, which can be used consistently on any machine / operating system (e.g. using Python’s os.environ). This is what I’ve been doing until now, generally storing the keys themselves in Keepass and typing them into the shell manually using export.
Using a .env File
Instead of manually typing these keys each time, I found a good convention from Epicodus that I’m going to start using.
Create a .env file in the Git repo of you application, and be sure to include .env in your .gitignore file. On each line of this file, include the export KEY=<VALUE> line to declare all needed environment variables.
Now, at the beginning of each development session, instead of manually typing export for each specific key, just use source .env to load all your API keys.
Considerations
Please note that this method only secures against accidental key exposure in source code and version control, it will not protect against someone with root control to your box.